Khi xây dựng một hệ thống RAG (Retrieval-Augmented Generation), chúng ta thường tập trung rất nhiều vào việc tối ưu hóa khâu truy xuất (retrieval) để tìm được ngữ cảnh (context) chính xác nhất. Tuy nhiên, có một bước quan trọng không kém, quyết định trực tiếp đến chất lượng đầu ra, đó chính là hậu xử lý (post-processing).
Nếu bỏ qua bước này, câu trả lời bạn nhận được từ LLM có thể khá "thô", đi kèm những vấn đề như:
- Chứa "chuỗi suy luận" không cần thiết (ví dụ: "Okay, let me analyze...").
- Câu trả lời lan man, không đi thẳng vào vấn đề.
- Tạo ra thông tin không có trong ngữ cảnh (hiện tượng "ảo giác" - hallucination).
- Không trích dẫn nguồn, làm giảm độ tin cậy.
Đây chính là lúc kỹ thuật hậu xử lý phát huy vai trò. Bài viết này sẽ đi sâu vào các phương pháp thiết yếu giúp bạn "tinh chế" output của LLM, biến nó thành một câu trả lời hoàn thiện.
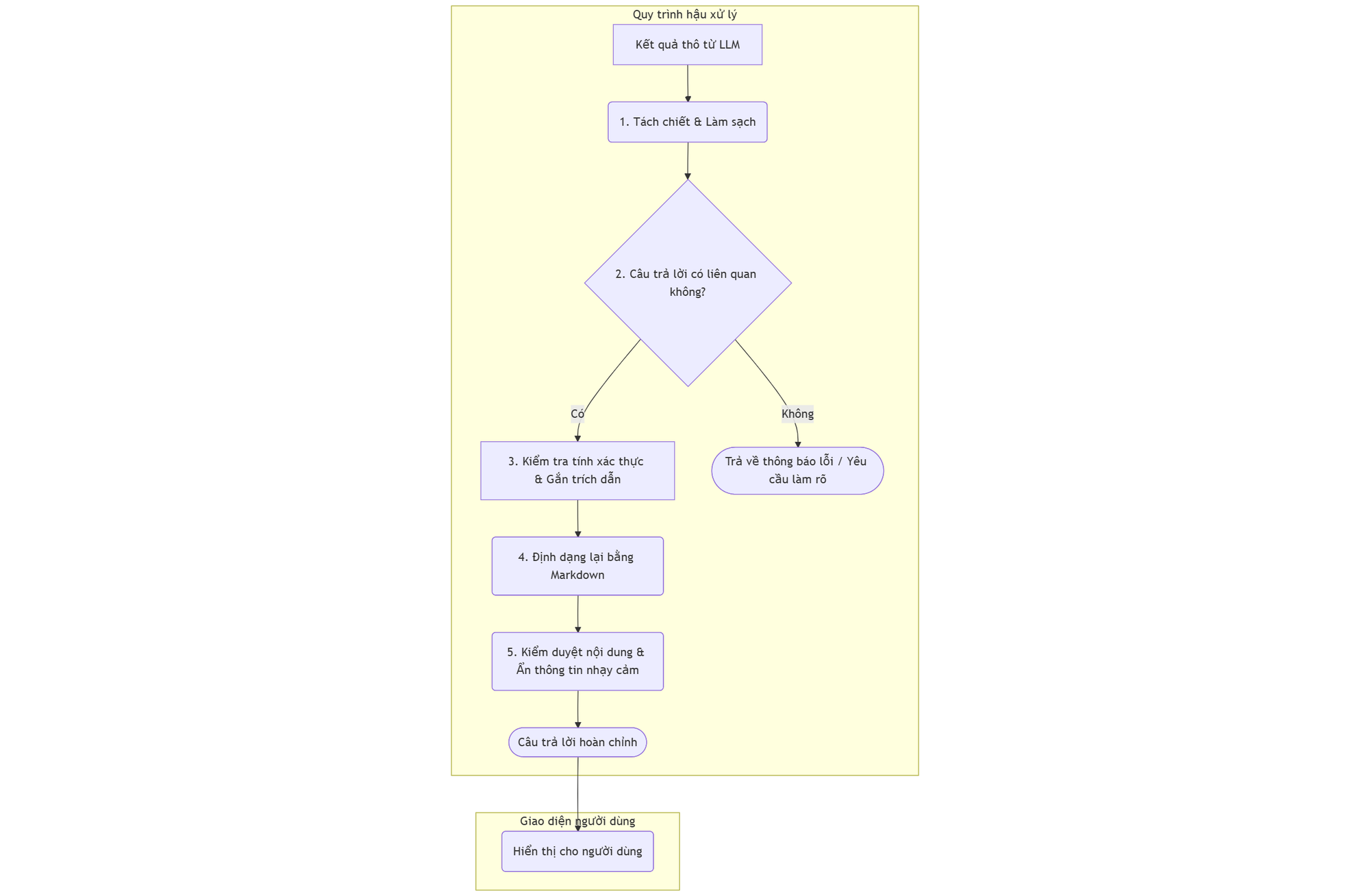
Luồng xử lý RAG hoàn chỉnh:Truy vấn -> Truy xuất ngữ cảnh -> LLM tạo sinh (Kết quả thô) -> **[QUY TRÌNH HẬU XỬ LÝ]** -> Câu trả lời cuối cùng
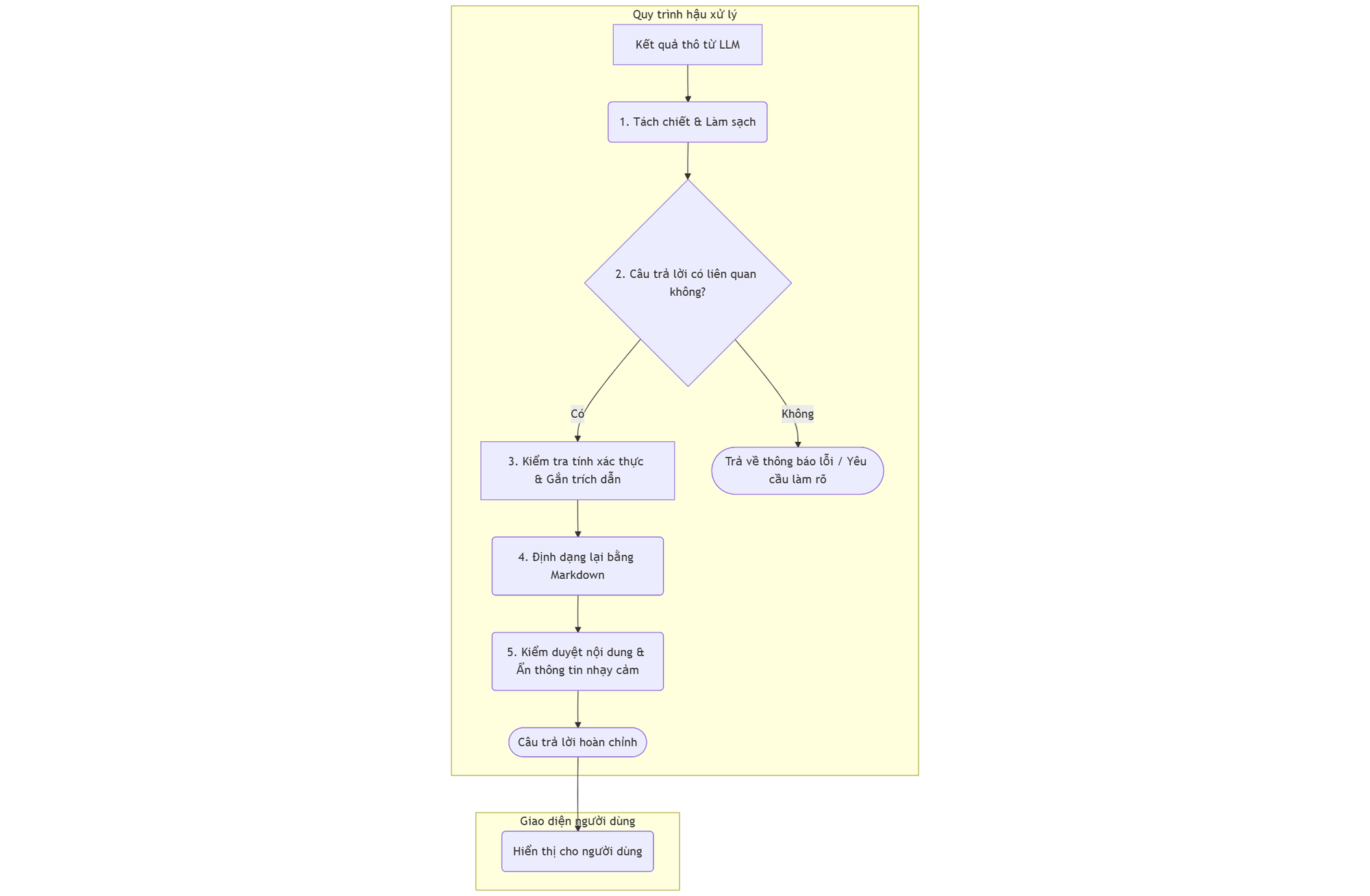
Các kỹ thuật hậu xử lý cần quan tâm
1. Tách chiết và làm sạch câu trả lời
Đây là bước cơ bản nhất để loại bỏ các phần "nhiễu" và chỉ giữ lại nội dung cốt lõi.
- Mục tiêu: Loại bỏ các câu dẫn, chuỗi suy luận, và chỉ giữ lại phần nội dung trả lời chính.
- Dùng dấu phân cách (Delimiters): Yêu cầu LLM trong prompt đặt câu trả lời vào trong các thẻ đặc biệt. Ví dụ:
<answer>Nội dung câu trả lời ở đây</answer>. Sau đó, bạn chỉ cần dùng code để trích xuất nội dung bên trong thẻ này. - Yêu cầu định dạng JSON: Đây là phương pháp hiệu quả và đáng tin cậy nhất. Bạn yêu cầu LLM trả về một đối tượng JSON có cấu trúc rõ ràng.
- Dùng dấu phân cách (Delimiters): Yêu cầu LLM trong prompt đặt câu trả lời vào trong các thẻ đặc biệt. Ví dụ:
Cách thực hiện:
{
"reasoning": "Các bước suy luận của mô hình...",
"final_answer": "Câu trả lời cuối cùng, sạch sẽ cho người dùng.",
"sources": ["tai_lieu_1.pdf", "trang_web_2.html"]
}
2. Kiểm tra tính xác thực dựa trên nguồn (Groundedness Check)
Đây là "lá chắn" quan trọng nhất để chống lại hiện tượng "ảo giác" của LLM, đảm bảo mọi thông tin đều đáng tin cậy.
- Mục tiêu: Đảm bảo mọi ý khẳng định trong câu trả lời đều được hỗ trợ bởi các văn bản đã được truy xuất.
- Cách thực hiện:
- Chia nhỏ câu trả lời: Tách câu trả lời thành các mệnh đề hoặc các ý khẳng định riêng lẻ (claims).
- Xác thực từng mệnh đề: Với mỗi mệnh đề, dùng một LLM call khác (hoặc một mô hình NLI) để kiểm tra xem nó có được xác thực bởi ngữ cảnh không.
- Lọc và tổng hợp lại: Chỉ giữ lại những mệnh đề đã được xác thực để tạo thành câu trả lời cuối cùng.
3. Thêm trích dẫn nguồn (Citation Generation)
Minh bạch về nguồn gốc thông tin là chìa khóa để xây dựng lòng tin với người dùng.
- Mục tiêu: Gắn các tài liệu tham khảo vào từng phần của câu trả lời.
- Cách thực hiện:
- Trong quá trình kiểm tra tính xác thực ở bước 2, khi một mệnh đề được xác nhận là đúng, hãy ghi lại nguồn ngữ cảnh đã xác thực nó.
- Thêm các chỉ mục trích dẫn vào cuối câu trả lời.
- Ví dụ: "Doanh thu quý 4 tăng 15% so với cùng kỳ năm ngoái [1]. Động lực tăng trưởng chính đến từ sản phẩm mới ra mắt [2]."
- Phía dưới sẽ là danh sách nguồn tham khảo tương ứng.
4. Kiểm tra tính liên quan (Relevance Check)
Đôi khi LLM trả lời đúng, nhưng lại không hoàn toàn khớp với câu hỏi ban đầu của người dùng.
- Mục tiêu: Đảm bảo câu trả lời cuối cùng giải quyết trực tiếp câu hỏi được đặt ra.
- Cách thực hiện:
- So sánh vector embedding: Tính toán độ tương đồng (cosine similarity) giữa vector của câu hỏi gốc và câu trả lời được tạo ra. Nếu điểm số quá thấp, câu trả lời có thể đã lạc đề.
- Dùng một LLM call đơn giản: Hỏi LLM một câu hỏi xác nhận:
"Câu trả lời sau có trực tiếp trả lời cho câu hỏi gốc không? Trả lời Có hoặc Không."
5. Định dạng và kiểm duyệt
Bước cuối cùng là đảm bảo câu trả lời không chỉ đúng mà còn an toàn và dễ đọc.
- Mục tiêu: Chuyển đổi văn bản thô thành định dạng thân thiện (in đậm, danh sách, bảng...) và loại bỏ các thông tin nhạy cảm.
- Cách thực hiện:
- Định dạng: Dùng một LLM call cuối cùng để yêu cầu định dạng lại văn bản bằng Markdown.
- Kiểm duyệt: Sử dụng các API kiểm duyệt nội dung hoặc dùng Regex để tìm và ẩn các thông tin định danh cá nhân (PII) như số điện thoại, email, CCCD...
Lời kết
Hậu xử lý không phải là một bước tùy chọn, mà là một tập hợp các lớp kiểm soát chất lượng giúp hệ thống RAG của bạn trở nên mạnh mẽ, chính xác và chuyên nghiệp. Bằng cách đầu tư vào quy trình này, bạn sẽ cung cấp cho người dùng một trải nghiệm vượt trội, với những câu trả lời không chỉ thông minh mà còn cực kỳ đáng tin cậy.
Nội dung được tạo bởi Google Chat A.I